Beyond Karpathy's LLM-Wiki: The Necessity of Cognitive Governance
I recently handed an LLM compiler three hundred files of reading notes, book highlights, and lecture fragments accumulated over twenty years. The system worked exactly as designed: it parsed each source, extracted key claims, organized them into a directory of interlinked Markdown files. When I sat down to review the output, every file was accurate, well-formatted, and completely useless.
The notes on Simon Sinek read like a textbook summary. The notes on René Girard read like a Wikipedia entry. The notes on Stanley Cavell, the philosopher I spent a decade studying, read like something written by a diligent undergraduate who had never been troubled by a single sentence Cavell wrote. Three hundred files of consensus. A searchable hard drive with better formatting.
Andrej Karpathy, who recently published a concept he calls the llm-wiki, diagnosed half of this problem. His engineering instinct lands on something important: the standard AI workflow is broken at the infrastructure level.
The Compiler Metaphor
In Retrieval-Augmented Generation (RAG), the AI searches a database at the exact moment you ask a question. It is a frantic, just-in-time operation, erratic and structurally blind. Karpathy's compiler approach refuses this. Instead, you give the LLM raw inputs (articles, notes, PDFs) and it works in the background to compile them into a dense, interlinked web of Markdown files. When you sit down to work, the knowledge is already synthesized. An ahead-of-time operation. As Karpathy puts it: "the wiki is a persistent, compounding artifact," not something re-derived on every query.
I had been independently experimenting with a similar approach for months, and his post validated the core engineering intuition. A compiler that runs before the conversation starts is categorically superior to a search engine that scrambles during it. (I wrote about the broader workspace architecture in The Agentic Studio.)
But a compiler is only as good as the architecture it targets. And this is where the engineering frame, on its own, hits a ceiling.
The Docile Compiler
If you hand an LLM a folder of raw reading notes and tell it to "compile and structure" them, it will default to its baseline training distribution. It will build an encyclopedia.
You have seen this. You asked ChatGPT to analyze something you read, and the output came back as a book-jacket summary. You asked it to connect two ideas, and it returned a list of superficial similarities. You have a hundred notes in Notion, and every time you ask the AI to "synthesize," the result is more generic than any of the individual notes. The machine averages. That is what it was trained to do.
In the Hacker News discussion around Karpathy's post, a commenter named qaadika raised the sharpest objection: "There's nothing 'personal' about a knowledge base you filled by asking AI questions." The worry is that the bookkeeping the LLM automates (filing, cross-referencing, summarizing) is exactly where genuine understanding forms. Hand it to a machine and you get a corpus that looks organized but has lost the intellectual labor that makes knowledge yours.
That worry is legitimate, but it mistakes the tool for the architecture. The fix is not to do all the bookkeeping by hand. It is to govern how the machine does it.
When I fed my un-governed compiler the notes on Sinek's The Infinite Game, the output looked like this:
Simon Sinek argues that leaders should maintain an infinite mindset rather than playing a finite game designed to beat competitors. He emphasizes building trust and advancing a Just Cause.
Accurate. Neutral. Philosophically sterile. A summary of what is, with no trace of what it means or what it fights against.
The default gravitational pull of the LLM runs toward consensus, toward the average of everything it has read, toward a fluency so frictionless that it erases the very tensions that make an idea worth having.
Left ungoverned, the compiler does not think. It smooths.
Cognitive Governance
Cognitive Governance is an explicit epistemological framework that dictates how the compiler fractures, weighs, and connects knowledge. Not just what to store, but how to reason about what it stores.
The LLM's natural gravity pulls toward consensus. The governance layer pulls against it. Every rule in the schema is a constraint that forces the machine to do something it would not do on its own: find antagonists, identify omissions, surface contradictions, link across disciplines. Governance is not organization. It is resistance: active, deliberate counter-pressure against the compiler's tendency to flatten everything into encyclopedia.
For my system, the governance architecture is a digital Zettelkasten, the note-linking method developed by the sociologist Niklas Luhmann, who used it to produce 58 books and hundreds of articles over 40 years. My workspace adapts it into three layers:
- Raw Sources (Immutable). Where my reading notes live, some of them fifteen years old. The AI reads these but is forbidden from modifying them.
- The Compiled Wiki (Mutable). The output layer. Instead of generic folders, the compiler operates strictly through Literature notes (LITs), Permanent concepts (ZETs), and Maps of Content (MOCs).
- The Schema (Governance). A `SCHEMA.md` file that forces the AI to execute specific protocols when it processes any source.
The mechanism only works if the rules are rigid. To prevent the smoothing effect, my Schema contains directives like this one:
Rule: Extraction over Summary Never summarize a text chronologically. Extract the structural claim and identify the text's implicit antagonist. Find the friction point. Link this claim to at least two existing concepts in the database.
When the compiler is governed by this single rule, the output on the same Sinek material transforms:
Sinek's "Finite Game" operates on the exact same mechanics as René Girard's theory of Mimetic Rivalry. A finite game requires an internal mediator, a competitor you are obsessed with beating. Sinek's "Infinite Game" is an attempt to escape mimetic contagion by replacing the localized competitor with an unachievable, transcendent "Just Cause." → [[MOC-Girardian-Mimesis]], [[LIT-Thiel-Zero-to-One]]
I had spent years reading both Sinek and Girard without ever making this connection explicit. The structural relationship was latent in my own notes, sitting across two folders that had never been in the same room. It took a governed compiler, one forced to find the friction point rather than summarize the surface, to make visible what was already mine but had never been articulated.
That is the difference between a compiler that files and one that generates. The architecture did not produce a new idea. It formalized a connection I had earned through years of reading but had never been forced to write down.
The bookkeeping is not eliminated. It is governed. The intellectual labor is encoded in the schema, not in the manual act of filing. And the schema is something only the human can write, because it reflects an epistemological commitment: what counts as a connection, what counts as friction, what the compiler should never be allowed to smooth over.
How to Build This
The novelty phase of generative AI is over. We are entering the infrastructural phase, and the tools you design today will shape the boundaries of what you can think tomorrow.
The evolution maps onto three stages:
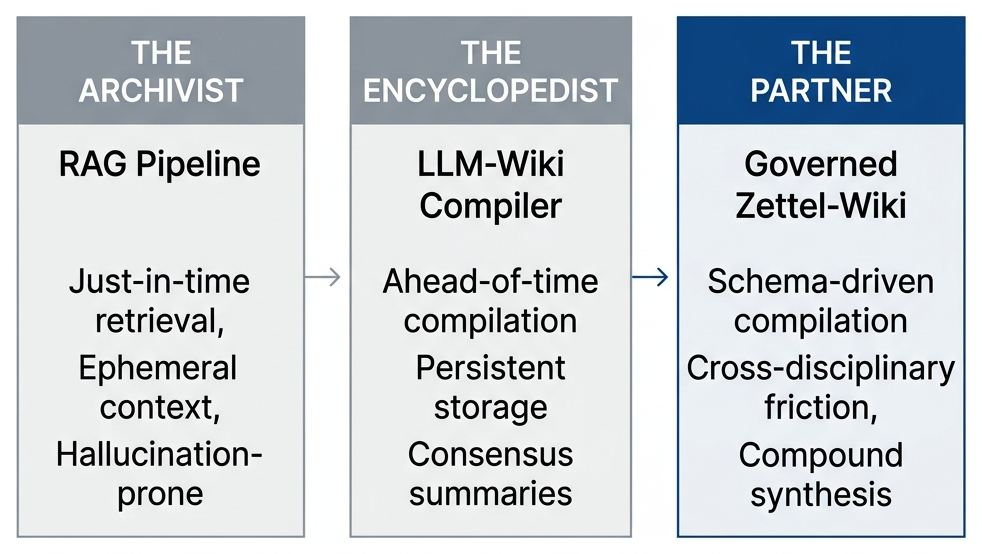
If your AI relies on a basic RAG pipeline, it is an archivist: fast, but structurally blind. If it acts as an un-governed compiler, it is an encyclopedist: organized, but gravitating toward consensus. An architected Zettel-Wiki is Stage 3: the compiler still does the heavy lifting, but the governance layer forces it to produce friction instead of fluency.
If you want to move from Stage 2 to Stage 3, here is what the transition requires.
1. Write a Schema file. This is the single most important document in the system. It contains the protocols the compiler must follow when processing any source. At minimum, include three rules: extraction over summary (force the compiler to identify structural claims, not retell the narrative), mandatory linking (every new node must connect to at least two existing nodes), and an antagonist rule (every claim must name what it argues against). Here is a minimal version you can paste into your own `SCHEMA.md` today:
## Ingest Protocol
When processing a new source:
1. Extract the source's central structural claim in one sentence.
2. Identify the claim's implicit antagonist: what position does this claim argue against?
3. Find the friction point: where does this claim create tension with existing nodes?
4. Link to at least two existing nodes (LIT or ZET). If no link exists, create a new ZET.
5. Never summarize chronologically. Never produce neutral description.2. Define your node types. Literature notes (one per source, capturing the source's central claim and its friction with your existing knowledge). Permanent notes (concept-level nodes that synthesize across multiple sources). Maps of Content (thematic indices that give you entry points into clusters of related ideas).
3. Make raw sources immutable. The compiler reads them but never modifies them. This preserves the original context and forces all synthesis into the compiled layer, where it can be audited and revised.
4. Run session reviews. After each working session, the AI summarizes what changed, proposes new links, and flags contradictions. Five minutes. The system gets smarter after every session.
The governance rules are not suggestions. They are instructions the machine executes. Natural language is the software layer, and your Schema is the program.
In the age of LLMs, the most valuable intellectual property you own is not the raw data in your notebooks. It is the Schema: the ruleset you write to govern how that data connects. When you get the rules right, the system ceases to be a tool. It becomes a partner that enforces consistency across a decade of your thought. It catches the contradictions you miss. It compiles, but more importantly, it compounds.
I have open-sourced the directory structure, governance schema, and ingest protocols I use in my own system. The repository includes the complete `SCHEMA.md`, worked examples of the ingest pipeline (raw source → LIT → ZET → MOC links), and the session review protocols.
If you want to try it now, this is the fastest path:
- Download the repository as ZIP from github.com/jonadas-tech/agentic-memory-template.
- Open the folder in your AI tool.
- Paste this command:
`Read START-HERE.md and run the full setup interview now.`
→ Open Source Template Repository
---
Sources & further reading
Andrej Karpathy, llm-wiki (2026). The original idea file. The engineering foundation is right; the governance layer is what this piece adds.
Sönke Ahrens, How to Take Smart Notes (2017). The modern codification of Niklas Luhmann's Zettelkasten method. The three-layer architecture described here is a digital adaptation of this system, with the LLM acting as the disciplined note-taker Ahrens describes.
Niklas Luhmann. The German sociologist who produced 58 books and hundreds of articles using a system of 90,000 interlinked index cards over 40 years. The original proof that structured note-linking compounds.
Jônadas Techio, The Agentic Studio (2026). The companion essay on building the full workspace architecture, from progressive disclosure to session reviews to style-guide-as-software.
Hacker News discussion on llm-wiki. The community debate on whether compilation is categorically different from RAG, and qaadika's sharp objection that bookkeeping is where understanding forms.
If you want essays like this in your inbox, subscribe.